
تبدیل دادههاابزارهایی مانند dbt ساخت خطوط لوله داده SQL را آسان و سیستماتیک میکنند. اما حتی با ساختار اضافه شده و مدلهای دادهای که به وضوح تعریف شدهاند، خطوط لوله هنوز هم میتوانند پیچیده شوند، که این امر مشکلات اشکالزدایی و اعتبارسنجی تغییرات در مدلهای داده را دشوار میکند.
پیچیدگی فزاینده منطق تبدیل دادهها، مسائل زیر را ایجاد میکند:
- فرآیندهای سنتی بررسی کد فقط تغییرات کد را بررسی میکنند و تأثیر دادهها بر این تغییرات را نادیده میگیرند.
- ردیابی تأثیر دادهها ناشی از تغییرات کد دشوار است . در DAGهای پراکنده با وابستگیهای تو در تو، کشف چگونگی و محل وقوع تأثیر دادهها بسیار زمانبر یا تقریباً غیرممکن است.
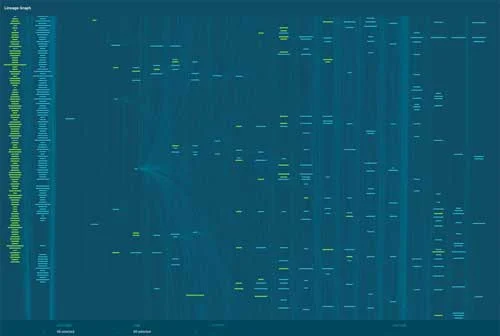
DAG مربوط به dbt گیتلب (که در تصویر بالا نشان داده شده است) نمونهی کاملی از یک پروژهی دادهای است که از قبل یک پروژهی آماده و بیدردسر است. تصور کنید که بخواهید یک تغییر منطقی سادهی SQL در یک ستون را در کل این DAG دنبال کنید. بررسی بهروزرسانی مدل داده، کار دلهرهآوری خواهد بود.
چگونه به این نوع بررسی نزدیک میشوید؟
اعتبارسنجی دادهها چیست؟
اعتبارسنجی دادهها به فرآیندی اشاره دارد که برای تعیین صحت دادهها از نظر الزامات دنیای واقعی استفاده میشود. این به معنای اطمینان از این است که منطق SQL در یک مدل داده با تأیید صحت دادهها، مطابق انتظار رفتار میکند. اعتبارسنجی معمولاً پس از اصلاح یک مدل داده، مانند تطبیق با الزامات جدید، یا به عنوان بخشی از یک بازسازی انجام میشود.
یک چالش بررسی منحصر به فرد
دادهها دارای حالتهایی هستند و مستقیماً تحت تأثیر تبدیلی قرار میگیرند که برای تولید آنها استفاده میشود. به همین دلیل است که بررسی تغییرات مدل داده یک چالش منحصر به فرد است، زیرا هم کد و هم دادهها نیاز به بررسی دارند.
به همین دلیل، بهروزرسانیهای مدل دادهها نه تنها باید از نظر کامل بودن، بلکه از نظر زمینه نیز بررسی شوند. به عبارت دیگر، اطمینان حاصل شود که دادهها صحیح هستند و دادهها و معیارهای موجود ناخواسته تغییر نکردهاند.
دو حد نهایی اعتبارسنجی دادهها
در بیشتر تیمهای داده، فردی که تغییر را ایجاد میکند، برای ارزیابی تأثیر و اعتبارسنجی تغییر، به دانش سازمانی، شهود یا تجربه گذشته متکی است.
«من تغییری در X ایجاد کردهام، فکر میکنم میدانم تأثیر آن چه باید باشد. با اجرای Y آن را بررسی خواهم کرد.»
روش اعتبارسنجی معمولاً در یکی از دو حالت افراطی قرار میگیرد که هیچکدام ایدهآل نیستند:
- بررسی موردی با کوئریها و برخی بررسیهای سطح بالا مانند تعداد ردیفها و طرحواره. سریع است اما خطر از دست دادن تأثیر واقعی را دارد. خطاهای بحرانی و خاموش میتوانند مورد توجه قرار نگیرند.
- بررسی جامع تک تک مدلهای پاییندستی. این کار کند و نیازمند منابع است و با رشد خط تولید میتواند پرهزینه باشد.
این امر منجر به یک فرآیند بررسی دادهها میشود که بدون ساختار، به سختی قابل تکرار است و اغلب خطاهای خاموشی را ایجاد میکند. به یک روش جدید نیاز است که به مهندس کمک کند تا اعتبارسنجی دقیق و هدفمند دادهها را انجام دهد.
رویکردی بهتر از طریق درک وابستگیهای مدل داده
برای اعتبارسنجی یک تغییر در یک پروژه داده، درک رابطه بین مدلها و نحوه جریان دادهها در پروژه مهم است. این وابستگیهای بین مدلها به ما اطلاع میدهند که چگونه دادهها از یک مدل به مدل دیگر منتقل و تبدیل میشوند.
تحلیل روابط بین مدلها
همانطور که دیدیم، DAGهای پروژههای داده میتوانند بسیار بزرگ باشند، اما تغییر مدل داده فقط زیرمجموعهای از مدلها را تحت تأثیر قرار میدهد. با جداسازی این زیرمجموعه و سپس تجزیه و تحلیل رابطه بین مدلها، میتوانید لایههای پیچیدگی را کنار بزنید و با توجه به یک تغییر منطق SQL خاص، فقط روی مدلهایی تمرکز کنید که واقعاً نیاز به اعتبارسنجی دارند.
انواع وابستگیها در یک پروژه داده عبارتند از:
مدل به مدل
وابستگی ساختاری که در آن ستونها از یک مدل بالادستی انتخاب میشوند.
--- downstream_model
select
a,
b
from {{ ref("upstream_model") }}ستون به ستون
یک وابستگی به projection که یک ستون بالادستی را انتخاب، تغییر نام یا تبدیل میکند.
--- downstream_model
select
a,
b as b2
from {{ ref("upstream_model") }}مدل به ستون
یک وابستگی فیلتری که در آن یک مدل پاییندستی از یک مدل بالادستی در یک عبارت شرطی where، join یا هر عبارت شرطی دیگری استفاده میکند.
-- downstream_model
select
a
from {{ ref("upstream_model") }}
where b > 0درک وابستگیهای بین مدلها به ما کمک میکند تا شعاع تأثیر تغییر منطق مدل داده را تعریف کنیم.
شعاع برخورد را مشخص کنید
هنگام ایجاد تغییر در SQL یک مدل داده، مهم است که بدانید کدام مدلهای دیگر ممکن است تحت تأثیر قرار گیرند (مدلهایی که باید بررسی کنید). در سطح بالا، این کار توسط روابط مدل به مدل انجام میشود. این زیرمجموعه از گرههای DAG به عنوان شعاع تأثیر شناخته میشود.
در DAG زیر، شعاع تأثیر شامل گرههای B (مدل اصلاحشده) و D (مدل پاییندست) است. در dbt، این مدلها را میتوان با استفاده از انتخابگر modified+ شناسایی کرد.
شناسایی گرههای اصلاحشده و مدلهای پاییندست شروع بسیار خوبی است و با جداسازی تغییراتی مانند این، شما میتوانید حوزه اعتبارسنجی دادههای بالقوه را کاهش دهید. با این حال، این امر هنوز هم میتواند منجر به تعداد زیادی مدل پاییندست شود.
طبقهبندی انواع تغییرات SQL میتواند با درک شدت تغییر، به شما در اولویتبندی مدلهایی که واقعاً نیاز به اعتبارسنجی دارند، کمک کند و شاخههایی را که تغییراتی دارند که ایمن شناخته شدهاند، حذف کند.
تغییر SQL را طبقهبندی کنید
همه تغییرات SQL سطح ریسک یکسانی برای دادههای پاییندستی ندارند، و بنابراین باید بر این اساس طبقهبندی شوند. با طبقهبندی تغییرات SQL به این روش، میتوانید یک رویکرد سیستماتیک به فرآیند بررسی دادههای خود اضافه کنید.
یک تغییر SQL در یک مدل داده میتواند به عنوان یکی از موارد زیر طبقهبندی شود:
تغییر بدون وقفه
تغییراتی که بر دادههای مدلهای پاییندستی تأثیری ندارند، مانند اضافه کردن ستونهای جدید، تنظیمات قالببندی SQL یا اضافه کردن نظرات و غیره.
-- Non-breaking change: New column added
select
id,
category,
created_at,
-- new column
now() as ingestion_time
from {{ ref('a') }}تغییر جزئی-شکستگی
تغییراتی که فقط مدلهای پاییندستی را که به ستونهای خاصی ارجاع میدهند، تحت تأثیر قرار میدهند، مانند حذف یا تغییر نام یک ستون؛ یا اصلاح تعریف یک ستون.
-- Partial breaking change: `category` column renamed
select
id,
created_at,
category as event_category
from {{ ref('a') }}شکستن تغییر
تغییراتی که بر همه مدلهای پاییندستی تأثیر میگذارند، مانند فیلتر کردن، مرتبسازی یا تغییر ساختار یا معنای دادههای تبدیلشده.
-- Breaking change: Filtered to exclude data
select
id,
category,
created_at
from {{ ref('a') }}
where category != 'internal'اعمال طبقهبندی برای کاهش دامنه
پس از اعمال این طبقهبندیها، شعاع برخورد و تعداد مدلهایی که نیاز به اعتبارسنجی دارند، میتواند به طور قابل توجهی کاهش یابد.
در DAG فوق، گرههای B، C و F اصلاح شدهاند که منجر به ایجاد 7 گره میشود که نیاز به اعتبارسنجی دارند (C تا E). با این حال، هر شاخه شامل تغییرات SQL نیست که در واقع نیاز به اعتبارسنجی داشته باشد. بیایید نگاهی به هر شاخه بیندازیم:
گره C: تغییر بدون شکست
C به عنوان یک تغییر غیرقطعی طبقهبندی میشود. بنابراین نیازی به بررسی C و H نیست و میتوان آنها را حذف کرد.
گره B: تغییر جزئی-شکستگی
B به دلیل تغییر در ستون B.C1 به عنوان یک تغییر جزئی طبقهبندی میشود. بنابراین، D و E فقط در صورتی نیاز به بررسی دارند که به ستون B.C1 ارجاع داده شوند.
گره F: شکستن تغییر
اصلاح مدل F به عنوان یک تغییر اساسی طبقهبندی میشود. بنابراین، تمام گرههای پاییندست (G و E) باید از نظر تأثیر بررسی شوند. به عنوان مثال، مدل g ممکن است دادهها را از ستون بالادست اصلاحشده جمعآوری کند.
۷ گره اولیه در حال حاضر به ۵ گره کاهش یافتهاند که باید از نظر تأثیر دادهها بررسی شوند (B، D، E، F، G). اکنون، با بررسی تغییرات SQL در سطح ستون، میتوانیم این تعداد را حتی بیشتر کاهش دهیم.
محدود کردن بیشتر دامنه با استفاده از دودمان در سطح ستون
طبقهبندی تغییرات قطعی و غیرقطعی آسان است، اما وقتی صحبت از بررسی تغییرات جزئی قطعی میشود، مدلها باید در سطح ستون تحلیل شوند.
بیایید نگاه دقیقتری به تغییر جزئی در مدل B بیندازیم، که در آن منطق ستون c1 اصلاح شده است. این اصلاح میتواند به طور بالقوه منجر به تحت تأثیر قرار گرفتن ۴ گره پاییندستی شود: D، E، K و J. پس از ردیابی میزان استفاده از ستون در پاییندستی، این زیرمجموعه میتواند بیشتر کاهش یابد.
با دنبال کردن ستون B.c1 در پاییندست، میتوانیم ببینیم که:
- B.c1 → D.c1 یک وابستگی ستون به ستون (تصویر) است.
- D.c1 → E یک وابستگی مدل به ستون است.
- D → K یک وابستگی مدل به مدل است. با این حال، از آنجایی که D.c1 در K استفاده نمیشود، این مدل میتواند حذف شود.
بنابراین، مدلهایی که باید در این شاخه اعتبارسنجی شوند B، D و E هستند. به همراه تغییر بحرانی F و G پاییندست، کل مدلهایی که در این نمودار اعتبارسنجی میشوند F، G، B، D و E هستند، یا فقط ۵ مدل از مجموع ۹ مدل بالقوه تحت تأثیر.
نتیجهگیری
اعتبارسنجی دادهها پس از تغییر مدل، به خصوص در DAG های بزرگ و پیچیده، دشوار است. به راحتی میتوان خطاهای خاموش را نادیده گرفت و انجام اعتبارسنجی به یک کار دلهرهآور تبدیل میشود، زیرا مدلهای داده اغلب در مورد تأثیر در پاییندست مانند جعبههای سیاه به نظر میرسند.
یک فرآیند ساختار یافته و تکرارپذیر
با استفاده از این تکنیک اعتبارسنجی دادهها با آگاهی از تغییر، میتوانید ساختار و دقت را به فرآیند بررسی وارد کنید و آن را سیستماتیک و تکرارپذیر کنید. این کار تعداد مدلهایی را که باید بررسی شوند کاهش میدهد، فرآیند بررسی را ساده میکند و با اعتبارسنجی فقط مدلهایی که واقعاً به آن نیاز دارند، هزینهها را کاهش میدهد.